

Data Engineering is on a meteoric rise. As a proportion of jobs advertised in the UK, data engineering has more than doubled over that past two years. At 1.5%, that's nearly 2,200 open positions. By comparison, "Software Engineer" makes up about 4.6%. And "Project Manager" 3.1%.
Data Engineering is even more in-demand than web development (1.2%).
UPDATE 09 November 2020: For the six month period preceding 09 November, this proportion now stands at 1.86% up from 1.5% for the period preceding the original publication date of this article, 11 May 2020, and up from 1.13% for the same period in 2019. However, 1.86% now only represents about 900 open positions due to the overall slowing of the job market during the pandemic.
Job vacancy trend for Data Engineer in the UK Source: itjobwatch.co.uk
So clearly, data engineering is a valuable skill, but what is it? And how is it different from other similar skill sets?
An Overview
Most job descriptions mention Python(66%) and SQL(56%). Many refer to platforms like AWS(42%) and processes such as ETL(42%). But the essence of data engineering is creating pipelines that move data.
Every person, every piece of your business constantly generates data. Each event capturing company functions (and dysfunctions)--showing money earned, and money lost; social-media, 3rd party partnerships, goods received, orders shipped. But if that data is never seen, no insights are gained.
Data Engineering requires knowing how to derive value from data, as well as, the practical engineering skills to move data from point A to point B without adulteration.
Knowing how to access all of this data regardless of source or format is one key skill for a data engineer. Accessing data may require scraping the web, PDFs, or half a dozen differing flavors of SQL and no-SQL databases. Another skill is knowing how to move and store data in an efficient manner (both in terms of time and cost). Handling large volumes of data is a specialist skill. Most importantly, though, is preserving the value of the data.
Not all Data is Information
Data only has value if it can be understood. If I told you the weather today is category B0047 with a temperature of 0.756743, you'd smack me. Computers often give far more cryptic responses. Decrypting them requires to things: context and expertise.
Moreover, moving data from one system to another removes a lot of context. That context is often necessary for an expert to interpret that data. Many different system, many different experts, many interpretations. Good data engineering is about gathering that interpretation along with the data and presenting a unified view that all users can understand.
Data Engineering is an Evolution of Business Intelligence
Another term used to describe the concepts above is BI or "business intelligence".
Business Intelligence was the domain of large, international companies. Long ago only they had the money to store large volumes of data and the economic intensive to do so. Monstrous SQL servers whirled away on large corporate mainframes backed by vast storage area networks(SAN). Data would be dumped in from systems in New York, Los Angeles, London, Hong Kong, and Singapore as each went to sleep to be processed before the next morning. Analysts would pour over the data using expensive tools from established vendors like PowerBI and Crystal Reports.
But if the term "business intelligence" was so well-established, why the duplicate terminology? Well the short answer is the internet.
With the rise of the internet came many new applications that both used and collected data. For some of these applications, the volumes of data were just too large for any single database server. They became known as webscale applications. At the same time, the price of storing data was falling exponentially (and had been for some time). Then in 2002, Seth Gilbert and Nancy Lynch published a formal proof of what is now known as the CAP Theorem.
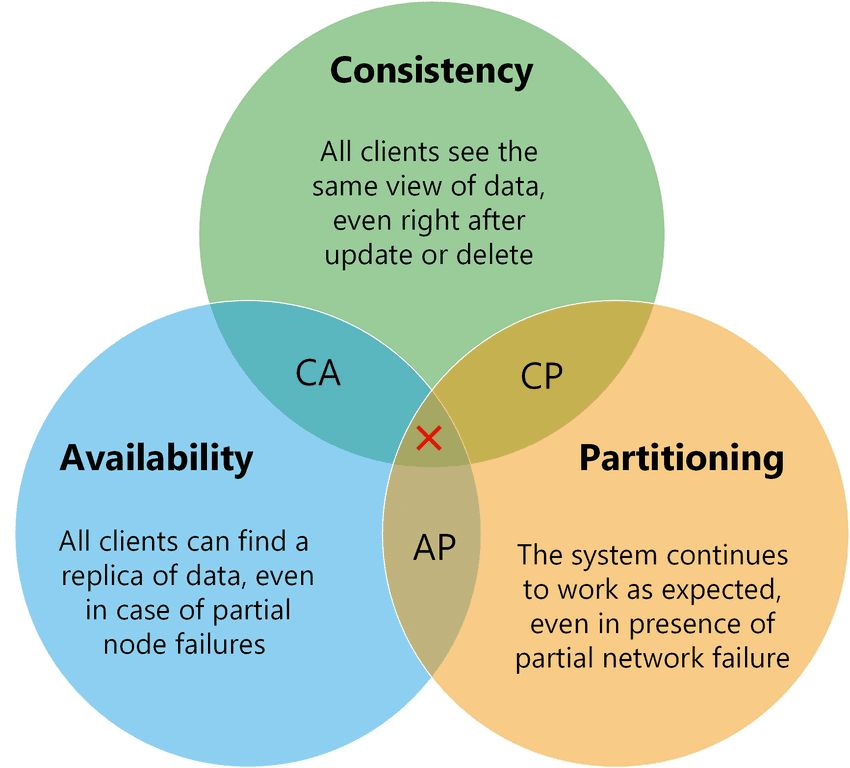
It states that when you partition your data across multiple servers, there is an inescapable trade-off between data being immediately available and receiving a consistent across those partitions. To take advantage of these new webscale opportunities, the new tools would be needed. Thus began the age of Big Data.
The Rise of the Big Data Engineer
Initial successes were in-house solutions by now tech-giants such as Google's Big Table; but soon the landscape was filled with open source solutions such as Memcached(2003), CouchDB(2005), and Hadoop(2006). A second wave followed in 2008-2009 with No-SQL databases such HBase, Cassandra, Redis, Riak, and MongoDB. Selling hardware and services to support these open source was, and still is, lucrative for companies such as Datastax and Hortonworks.
So what do you call someone who engineers solutions to big data problems? Well, you call them a "Big Data Engineer" of course.
Data Engineering and the Relative Fall of Big Data
Job vacancy trend for Big Data Engineer in the UK Source: itjobwatch.co.uk
With so many people making so much money with "Big Data" it became beyond buzz-worthy. The hype-train was running full steam and all were aboard. Many of the companies sold "Big Data", didn't have webscale data. Other, cheaper solutions would have served some clients better--begging the question, "just how big is big data"?
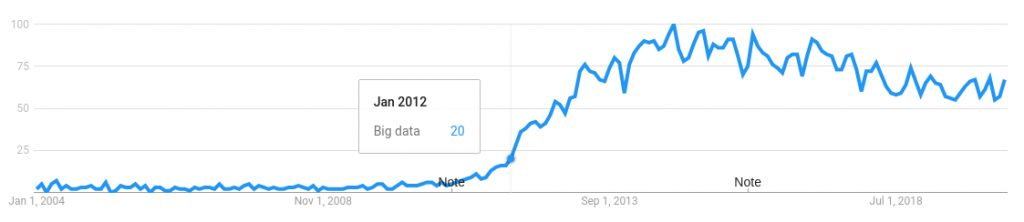
Google Trends: Big Data 2004-2020
Cooler heads now see these tools as part of the toolbox and use them judiciously. Dropping the "Big" from "Big Data Engineer" re-focuses on finding right solutions. It's also more in-line with the term, "Data Scientist"--I've never heard someone refer to themselves as a "Big Data Scientist".
Data Engineer Vs Data Scientist
Some people love dogs. Others love cats. Many love both.
All data engineers do some analytics. All data scientists do some programming. Some people are both; they conduct sophisticated analytics and write production-quality software. Looking into the job statistics yet again the difference is clear.
| Skill | Data Engineer | Data Scientist |
|---|---|---|
| Python | 66% | 91% |
| SQL | 56% | 47% |
| AWS | 42% | 42% |
| ETL | 42% | - |
| Big Data | 40% | 40% |
| Machine Learning | 19% | 75% |
| Statistics | - | 75% |
| Agile Software Development | 29% | - |
| Data Warehousing | 27% | - |
Frequency of Skill Appearing in Job Ads for Data Engineers and Scientists
Data Scientists are expected to be proficient in machine learning and statistics, but not agile software engineers. They are expect to know SQL, but not be database experts (hence no ETL or data warehousing).
Data Engineering is Still Evolving
These terms will continue to shift as technology evolves and the challenges we face change. The fun of the industry is that it is dynamic. There is always something new to learn.